-

New paper out today in the Journal of Neurolinguistics, discussing how a neural code for natural language syntax must be flexible enough to adapt to cases of cross-linguistic influence, given that only a minority of the world’s population is monolingual. We discuss the benefits of incorporating oscillatory neural mechanisms into the study of bilingual production…
-

My appearance on the Giant’s Shoulder podcast on YouTube, with Evan McGloughlin! We discussed philosophy of neuroscience, the mathematical structure of language, and the nature of intelligence.
-
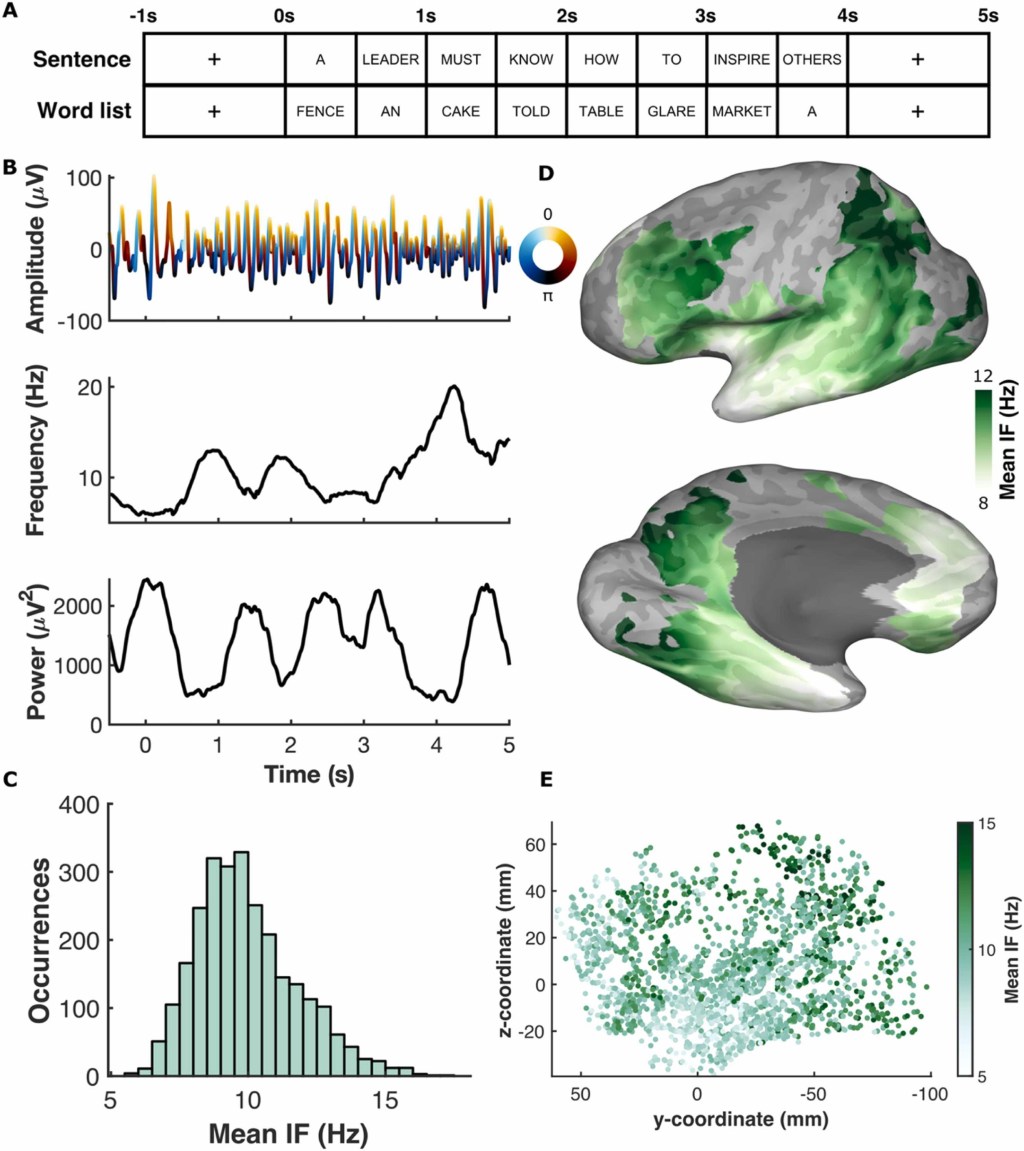
New intracranial EEG work on low frequency dynamics just appeared in Progress in Neurobiology. We used intracranial recordings in 32 participants to explore how the language network exports information to the default mode network during sentence reading. We discovered that alpha-band modulations index dynamic interactions between core language network and broader domain-general networks and may…
-

New paper out today in a volume edited by Adam Safron and Michael Levin (“World models in natural and artificial intelligence”). “A sentence is worth a thousand pictures: can large language models understand hum4n L4ngu4ge and the W0rld behind W0rds?” (with Evelina Leivada, Gary Marcus, and Fritz Günther) Volume link Paper link
-
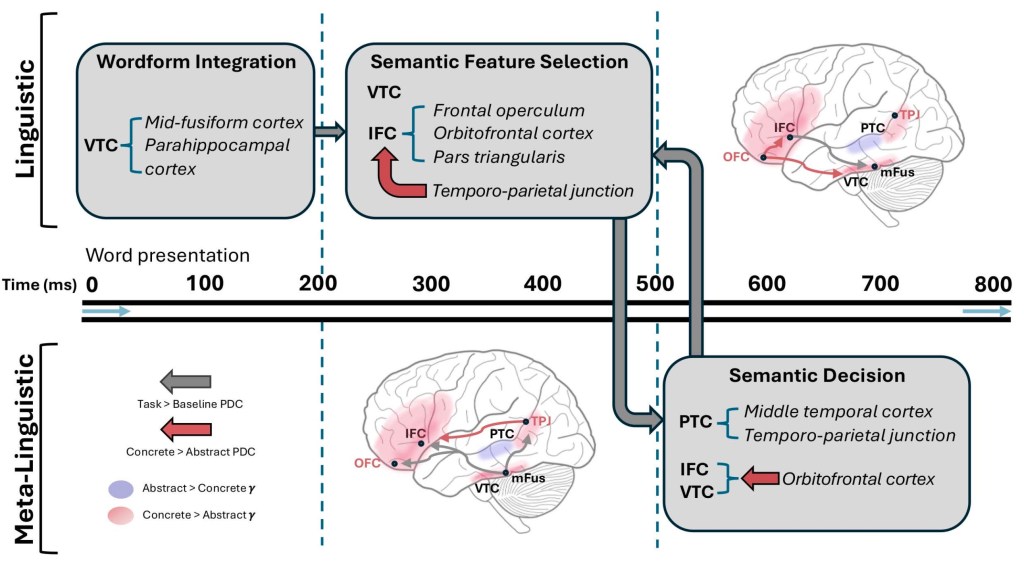
New intracranial EEG paper published in PLOS Biology, exploring single-word concreteness judgments during reading [PDF]: “Neurobiological models of conceptual processing have been limited in spatiotemporal resolution, and uncertainty remains about the causal role of specific regions in concept representation. We utilized intracranial recordings in human neurosurgical patients with epilepsy (n = 19) during a concreteness judgement paradigm…
-
A conversation with Jack Roycroft-Sherry on language evolution, semantics, and AI, on his podcast.
-

New book chapter published today for Vernon Press, ‘The quo vadis of the relationship between language and large language models’. With Vittoria Dentella and Evelina Leivada.
-
A review of Gregory Hickok’s latest book, Wired for Words, which focuses on topics in syntax and semantics. PDF available here, and link to journal here.
-
Subscribe
Subscribed
Already have a WordPress.com account? Log in now.
